Wholesale Marketing Strategy Ideas for Distributors
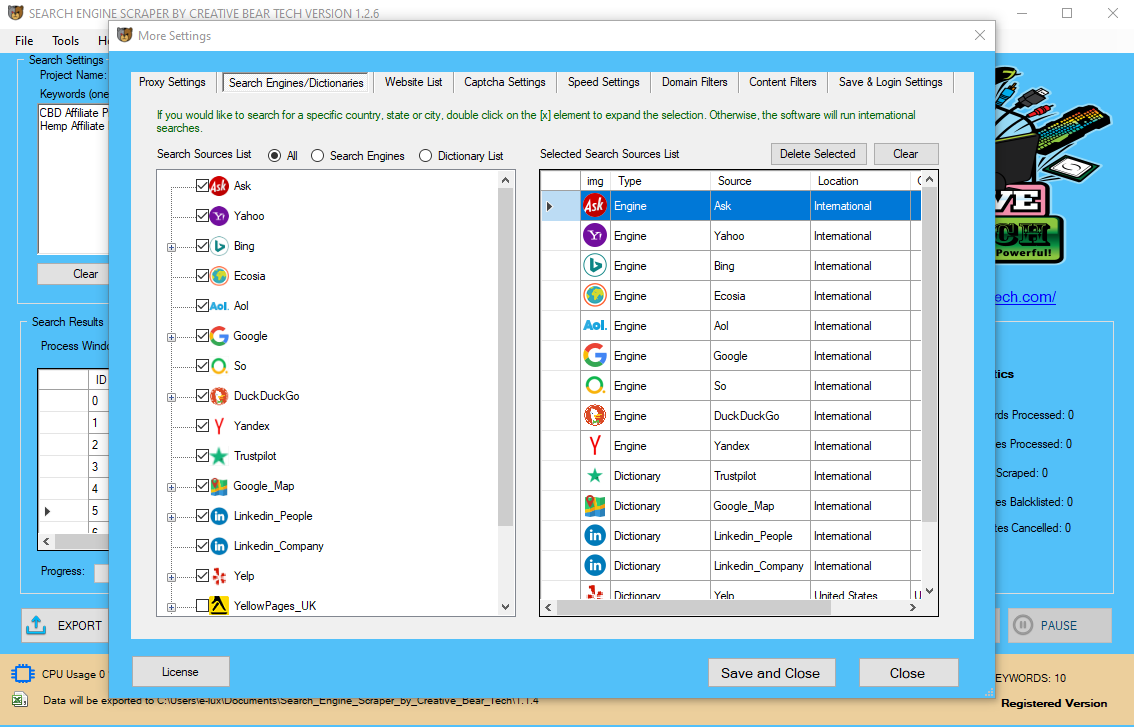
Content
Web Scraper Chrome Extension
JustCBD Responds to COVID19 by Donating Face Masks to Homeless - Miami Rescue Mission, Floridahttps://t.co/83eoOIpLFKhttps://t.co/XgTq2H2ag3 @JustCbd @PeachesScreams pic.twitter.com/Y7775Azisx
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
Using net scraping softwares you'll be able to build sitemaps that may navigate the site and extract the information. Using different sort of selectors the net scraping tool will navigate the positioning and extract multiple types of knowledge - text, tables, photographs, links and more. Web scraping also known as Web Data extraction / Web Harvesting / Screen Scrapping is a expertise which is liked by startups, small and massive companies. Spinn3r is a superb choice for scraping complete information from blogs, information sites, social media and RSS feeds. Spinn3r makes use of firehose API that manages 95% of the crawling and indexing work. It gives you the option to filter the information that it crawls utilizing key phrases, which helps in hunting down irrelevant content. The indexing system of Spinn3r is similar to Google and saves the extracted data in JSON format. Spinn3r works by constantly scanning the net and updating their data sets. Commonly, manual net scraping naturally arises out of a enterprise want. It may begin in the form of occasional copying and pasting of knowledge by enterprise analysts however eventually might turn into a formalized enterprise course of. Companies who select this option Generate Leads for Sales Teams have recognized a necessity for web scraped information however generally wouldn't have the technical expertise or infrastructure to mechanically collect it. All this whereas, we had been speaking of the distinction between using an API and web scraping. Each time you google a word or phrase, Google finds URL links from a list of collected seed URLs. A web crawler follows different hyperlinks, leaping to and from piles of data. An essential point to note, internet crawling requires net scraping, but scraping does not require crawling. In fundamental phrases, net scraping happens by a bot extracting knowledge from internet pages. However, selecting between net scraping vs API depends on your business objectives. If you need to gather knowledge from the same web site all the time, API is an acceptable selection. Basically, display scraping is sort of the same as internet scraping. The difference is that net scraping is used to extract knowledge from the websites, whereas display scraping is used for extracting data from required applications. 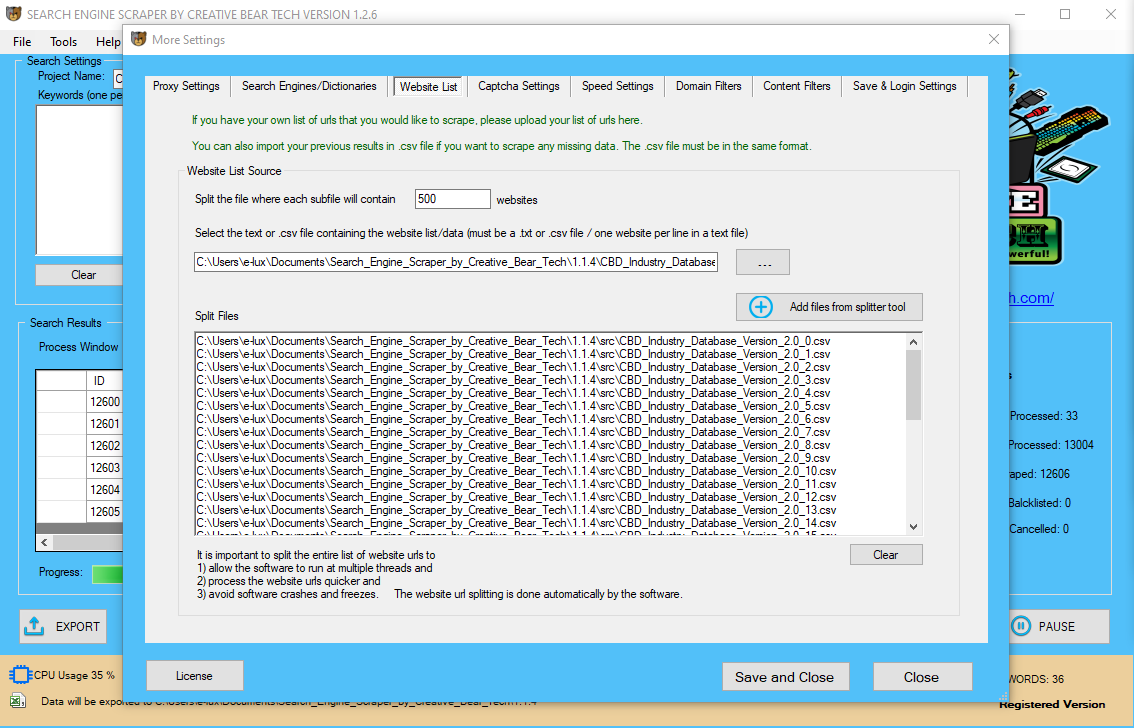 Every system you come across at present has an API already developed for their clients or it is no less than of their bucket list. While APIs are great if you really need to interact with the system but in case you are solely trying to extract knowledge from the website, web scraping is a much better choice. We talk about a few of the advantages of internet crawling over use of an API. This method can provide a fast and simple path to obtaining data while not having to program an API to the supply system. Ever since the world broad net started rising in terms of data measurement and quality, companies and knowledge lovers have been on the lookout for strategies to extract internet data easily. Today, there are various methods to acquire data from websites of your choice. Using API might be probably the greatest selections if you should interact with the system because it opens up information for builders or different users. Also, API doesn't at all times give entry to all of the available public data. These are essential points for corporations that want to collect loads of public information from the targeted websites. Web scraping is a process when an online scraper copies all the required information from varied internet pages and delivers outcomes for further use and evaluation. Nevertheless, given the shortage of options, display screen scraping has been used widely for numerous years. In the past, display screen scraping allowed third get together companies to entry monetary transaction data by logging into digital portals on behalf of a financial establishments' prospects. Typically display screen scraping involves the third celebration firm making a mirrored login web page, which looks and feels similar to a financial institution or credit card on-line login web page. The customer enters their login details, passwords and additional safety measures like memorable name, which the third party can use to log in because the buyer. Once logged into the account because the customer, screen scraping tools copy obtainable data to an exterior database and can be used outside of the monetary institution. The need to interface such a system to extra trendy methods is common. A robust answer will often require things no longer out there, such as source code, system documentation, APIs, or programmers with expertise in a 50-12 months-old computer system. In such instances, the only possible resolution may be to write a screen scraper that "pretends" to be a consumer at a terminal. A subtle and resilient implementation of this sort, constructed on a platform providing the governance and management required by a major enterprise—e.g. A scraper offers you the ability to drag the content material from a web page and see it organized in a simple-to-read document. Many suppliers provide scraping companies, so your organization can outsource web crawler instruments and concentrate on analysis instead of knowledge acquisition. Also, if your business has all of the sources for the information gathering process, you possibly can build your personal web scraper and use it on your corporations’ targets. Despite the usefulness of this know-how, shortcomings remain in safety and speed.
Every system you come across at present has an API already developed for their clients or it is no less than of their bucket list. While APIs are great if you really need to interact with the system but in case you are solely trying to extract knowledge from the website, web scraping is a much better choice. We talk about a few of the advantages of internet crawling over use of an API. This method can provide a fast and simple path to obtaining data while not having to program an API to the supply system. Ever since the world broad net started rising in terms of data measurement and quality, companies and knowledge lovers have been on the lookout for strategies to extract internet data easily. Today, there are various methods to acquire data from websites of your choice. Using API might be probably the greatest selections if you should interact with the system because it opens up information for builders or different users. Also, API doesn't at all times give entry to all of the available public data. These are essential points for corporations that want to collect loads of public information from the targeted websites. Web scraping is a process when an online scraper copies all the required information from varied internet pages and delivers outcomes for further use and evaluation. Nevertheless, given the shortage of options, display screen scraping has been used widely for numerous years. In the past, display screen scraping allowed third get together companies to entry monetary transaction data by logging into digital portals on behalf of a financial establishments' prospects. Typically display screen scraping involves the third celebration firm making a mirrored login web page, which looks and feels similar to a financial institution or credit card on-line login web page. The customer enters their login details, passwords and additional safety measures like memorable name, which the third party can use to log in because the buyer. Once logged into the account because the customer, screen scraping tools copy obtainable data to an exterior database and can be used outside of the monetary institution. The need to interface such a system to extra trendy methods is common. A robust answer will often require things no longer out there, such as source code, system documentation, APIs, or programmers with expertise in a 50-12 months-old computer system. In such instances, the only possible resolution may be to write a screen scraper that "pretends" to be a consumer at a terminal. A subtle and resilient implementation of this sort, constructed on a platform providing the governance and management required by a major enterprise—e.g. A scraper offers you the ability to drag the content material from a web page and see it organized in a simple-to-read document. Many suppliers provide scraping companies, so your organization can outsource web crawler instruments and concentrate on analysis instead of knowledge acquisition. Also, if your business has all of the sources for the information gathering process, you possibly can build your personal web scraper and use it on your corporations’ targets. Despite the usefulness of this know-how, shortcomings remain in safety and speed.
Finally, web sites could make use of technologies, corresponding to captchas, particularly designed to make scraping difficult. Depending on the policies of the online scraper, technical workarounds could or will not be employed. Automated net scraping offers numerous advantages over handbook assortment. Data collected by a scraper is a comprehensive highlight reel while data from a crawler is extra of a mathematical index. In order to ascertain who or what needs the help of a scraper, we are able to return to the grand scale of what information crawling means. When net browsers like Bing and Google use the technology for their own use, then you'll be able to imagine net crawling as a person isn’t super sensible. For instance, Google has a lot info housed of their databases that they even have on-line sources for key phrases.
Personal Tools
Second, web sites can change with out discover and in surprising ways. Web scraping projects should be set up in a method to detect modifications after which have to be up to date to accurately collect the same data. Here are some of the finest information acquisition software out there out there right now. Today, organizations trying to access net data programmatically use a way referred to as net scraping. Unfortunately, net scraping instruments are incomplete and insufficient to deliver on the promise of Web data. In this tutorial we shall be focusing on the Beautiful Soup module. The final level to notice is the way crawling is worried with minimizing the amount of duplicated information. While a scraper isn’t necessarily involved with the information itself, a crawler is out to eliminate the issue of delivering the same data greater than as soon as. This excessive-stage side of web crawling is one of the reasons why the process is carried out on larger ranges. After all, the extra info a crawler has to look through, the higher the chance for duplicate data there may be. The bot seems for probably the most helpful data and ranks that information for you. Think of internet scraper as a musician, studying only their favourite classical compositions. They can only entry a fraction of the information on the web, they provide little in the way of information quality, and should nonetheless be built-in with other instruments to ship real worth. This leaves organizations either missing the chance to leverage internet knowledge or with incomplete information access, poor data quality, unreliable and old-fashioned data, excessive costs and uncertain business dangers. FMiner is one other in style software for internet scraping, knowledge extraction, crawling display screen scraping, macro, and web help for Window and Mac OS. Many knowledge evaluation, huge information, and machine studying initiatives require scraping websites to gather the info that you just’ll be working with. The Python programming language is extensively used within the data science group, and therefore has an ecosystem of modules and tools that you need to use in your personal initiatives.
Welcome To The #1 Ultimate Guide To Web Scraping
Instead of writing custom code, customers merely load an online page right into a browser and click to identify information that should be extracted right into a spreadsheet. If the reply to either of these questions is "Yes," then your business may be a great candidate to implement a web scraping technique. Web scraping might help your small business make higher-informed decisions, attain focused leads, or monitor your rivals. First, our group of seasoned scraping veterans develops a scraper unique to your project, designed specifically to focus on and extract the info you want from the web sites you want it from. Open Banking was designed to exchange display scraping as a safer, quicker, and higher various. With the arrival of PSD2 laws coming into effect in September of 2019, display screen scraping will not be a viable approach to access monetary institution transaction information. For corporations who want or want to access account information but have yet to undertake Open Banking, the looming deadline should push them to undertake this newest innovation in financial expertise. Web scrapers automatically gather data and data that’s normally solely accessible by visiting an internet site in a browser. Large swimming pools of information can take screen scraping instruments 5–10 minutes to retrieve. Passwords and additional security data, as soon as passed to a 3rd celebration, becomes extra vulnerable to loss. As screen scraping instruments usually scan the present client-going through net portals of financial suppliers, a small change to a web site can create stability points for display screen scraping tools. Continuity of access can turn out to be a major issue for businesses relying upon scraped knowledge. 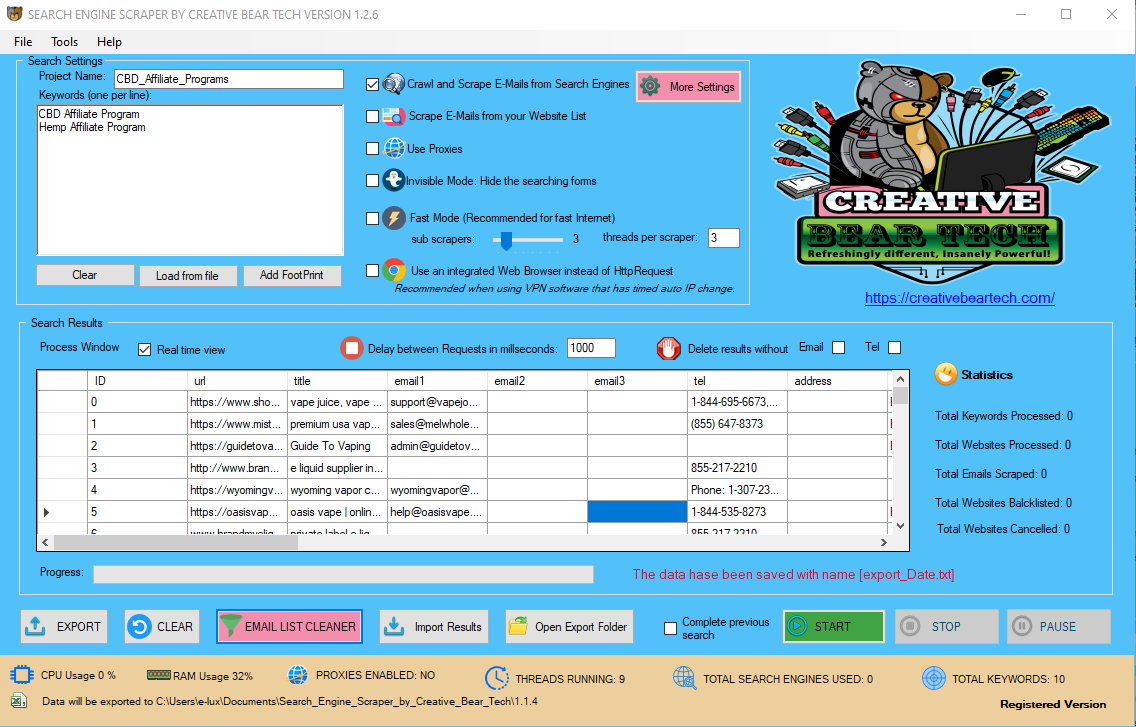 But meaning we hope that every website will allow you to access their saved information by each the means. Very few web sites will actually allow you to access their information (even if meaning limited or managed information). This means if you end up on to arrange your personal fashion E-Commerce store and attempt to get data from your competitors, you will obviously find no APIs and must code customised scrapers.
But meaning we hope that every website will allow you to access their saved information by each the means. Very few web sites will actually allow you to access their information (even if meaning limited or managed information). This means if you end up on to arrange your personal fashion E-Commerce store and attempt to get data from your competitors, you will obviously find no APIs and must code customised scrapers.
Grow your wholesale CBD sales with our Global Hemp and CBD Shop Database from Creative Bear Tech https://t.co/SQoxm6HHTU#cbd #hemp #cannabis #weed #vape #vaping #cbdoil #cbdgummies #seo #b2b pic.twitter.com/PQqvFEQmuQ
— Creative Bear Tech (@CreativeBearTec) October 21, 2019
- It is among the hottest ways to exchange information between companies.
- Web pages are built using text-primarily based mark-up languages (HTML and XHTML), and frequently contain a wealth of helpful information in textual content kind.
- Web scraping is a method to assemble large amounts of knowledge from various internet pagesTo put it simply, some websites present APIs that give access for builders to receive the particular knowledge from net pages.
- Usually, companies make collaboration agreements to accumulate permissions to entry API supplier data.
- However, most net pages are designed for human end-customers and never for ease of automated use.
Connect clear structured web knowledge to your favorite Business Intelligence tools, with out the hassle of growing or sustaining knowledge collection processes. The most time-consuming and brittle process of gathering enterprise insights is the gathering and cleansing of net knowledge. DataHen streamlines and standardizes the method via customizable and scalable platform and services. So, it is a process of accumulating data routinely from the World Wide Web. Current web scraping options vary from the advert-hoc, requiring human effort, to even absolutely automated methods which are capable of convert complete web pages into structured information. To reiterate a number of factors, web scraping extracts established, ‘structured knowledge.’ You should have identified we’d circle back to that all-important level. And don’t neglect, web scraping can be an isolated occasion, whereas net crawling combines the 2. Moving even deeper into the topic, scraping vs crawling is the distinction between collection and computation. Collection is beneficial when all one requires is knowledge, however computation digs additional into the quantity of knowledge out there. Streamlining the analysis process and minimizing the arduous task of gathering information is a huge advantage of utilizing a web scraper. If your sole intent and purpose are to extract knowledge from a selected web site, then an information scraper is the perfect on-line tool for you. When faced with a choice between web scraping vs net crawling, think about the type of information you should extract from the internet. Manual web scraping the method of manually copying and pasting knowledge from web sites into spreadsheets. By doing this autonomously, net scraping scripts open up a world of potentialities in data mining, knowledge evaluation, statistical analysis, and much more. Report mining is the extraction of information from human-readable computer reports. Conventional information extraction requires a connection to a working supply system, suitable connectivity requirements or an API, and usually complex querying. By utilizing the supply system's commonplace reporting choices, and directing the output to a spool file instead of to a printer, static stories could be generated suitable for offline evaluation via report mining. This method can keep away from intensive CPU usage throughout enterprise hours, can minimise end-user licence costs for ERP prospects, and might supply very fast prototyping and growth of customized stories. Whereas information scraping and internet scraping contain interacting with dynamic output, report mining includes extracting data from recordsdata in a human-readable format, such as HTML, PDF, or text. These may be simply generated from nearly any system by intercepting the data feed to a printer. Web pages are constructed using textual content-based mark-up languages (HTML and XHTML), and frequently comprise a wealth of helpful information in textual content type. However, most internet pages are designed for human end-users and never for ease of automated use. Because of this, device kits that scrape net content material have been created. A net scraper is an API or software to extract data from a website online. Companies like Amazon AWS and Google present net scraping instruments, services, and public data obtainable free of value to end-users. Both net scraping and robotic course of automation check with the automation of tasks that could be accomplished manually. UiPath and Kofax are two such examples of main RPA software platforms. Keep these few ideas about net scraping vs web crawling behind your thoughts before diving into your next analysis project. Web crawling is an important a part of how search engines like google function. Web scraping and internet crawling refer to similar however distinct actions. Web scraping focuses on the extraction of information from web pages whereas web crawling simply refers to the automated means of visiting many pages of 1 or multiple websites based on a set of rules. Thus, an online scraping project could or could not involve net crawling and vice versa. What could be much simpler is to take the help of a well-experienced staff like PromptCloud whom you can simply present with your necessities. Data scraping could be scaled to suit your explicit needs, that means you possibly can scrape more websites should your organization require more information on a sure topic. All that extracted information offered to you with minimal effort on your part.
Global Hemp Industry Database and CBD Shops B2B Business Data List with Emails https://t.co/nqcFYYyoWl pic.twitter.com/APybGxN9QC
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Keep that phrase at the back of your mind when mulling over the variations between internet scraping vs net crawling. Choosing a solution that directly accesses the API somewhat than rendering the corresponding desktop page means decrease hardware and software program prices in addition to fewer pissed off prospects and missed gross sales alternatives. A data analyst or knowledge scientist doesn’t always get data handed to them in a CSV or through an simply accessible database. Consultation with an experienced web scraper may help you uncover what is possible. First, particular person web sites could be difficult to parse for a wide range of causes. Websites could load slowly or intermittently, and their data could also be unstructured or found inside PDF files or pictures. This creates complexity and ambiguity in defining the logic to parse the location. Keywords that lead you to different keywords, which lead you to more key phrases. Keywords break down subjects additional and additional till they're as particular to a subject as attainable. Whew, that’s quite a journey we just went on, maybe a journey much like the one an internet crawler goes on every time the bot finds new URLs to look by way of. When discussing web scraping vs internet crawling, it’s essential to remember how a crawler is used by massive firms. Another challenge with cell optimisation and display-scraping is efficiency. Each notice is information applicable to the subject or topics you’re plucking by way of. Web scraping, for the most part, is used to find structured information. ‘Structured knowledge’ can include something from inventory info to company telephone numbers. First and foremost, an automated course of can collect knowledge much more effectively. Much more data could be collected in a much shorter time compared to handbook processes. It has an admin console filled with features that permits you to perform searches on the raw data. Spinn3r is an ideal solution in case your knowledge requirements are restricted to media web sites. Web scraping instruments are specially developed software program for extracting useful data from the web sites. These tools are useful for anyone who's looking to acquire some type of information from the Internet. The real problem is that customers have knowledge in too many different sorts of siloes. This quantity of customisation is simply not attainable with an API. When you go together with a web site’s API, you are limited in so some ways with little to no customisation choices. If internet scraping is best than APIs, why do most individuals proceed to make use of APIs?
Best Software Tools To Acquire Web Data Without Coding
Second, it additionally eliminates the potential for human error and might perform complex data validation to further guarantee accuracy. Finally, in some circumstances, automated internet scraping can seize information from internet pages that is invisible to normal customers. Most generally, programmers write custom software program packages to crawl particular web sites in a pre-decided trend and extract knowledge for a number of specified fields. Customer information is not a battleground between banks and data aggregators, or between display scraping and APIs. It's an opportunity for banks to remain the primary financial advisor to prospects, to empower customers and to turn out to be a digital financial institution of the future. Web scraping is a method to assemble massive amounts of knowledge from various internet pagesTo put it merely, some websites present APIs that give access for builders to obtain the specific data from net pages. It is among the most popular ways to trade information between businesses. Usually, firms make collaboration agreements to acquire permissions to access API provider information. But the truth is that many purchasers do want to share their data, and we count on this pattern to proceed and amplify. APIs are a much better method for purchasers to share knowledge than display screen scraping because customers haven't got to offer away their usernames and passwords to nonbanks. I even have written analysis on the usage of APIs within the banking trade for a few years now and am keen about their capability to transform the industry. But there may be far more at stake here than display screen scraping versus APIs, and banks' unease about sharing buyer information. Newer types of internet scraping contain listening to knowledge feeds from net servers. For example, JSON is commonly used as a transport storage mechanism between the shopper and the webserver.
Scraping A Website With Python
Some are meant for hobbyists and some are appropriate for enterprises. If you need knowledge from a couple of web sites of your selection for quick research or project, these tools are more than sufficient. DIY tools are a lot simpler to use compared to programming your own data extraction setup. As a concrete example of a basic display scraper, think about a hypothetical legacy system relationship from the Nineteen Sixties—the daybreak of computerized information processing. Computer to consumer interfaces from that era had been often simply text-primarily based dumb terminals which were not much more than virtual teleprinters (such methods are still in use today[update], for various reasons). The capacity to collect distinctive data sets can actually set you other than the pack, and having the ability to access APIs and scrape the online for brand new information tales is one of the simplest ways to get information no person else is working with. The third choice is to use a self-service level-and-click on software program, such as Mozenda. Many corporations maintain software program that enables non-technical business users to scrape websites by constructing projects utilizing a graphical person interface (GUI). 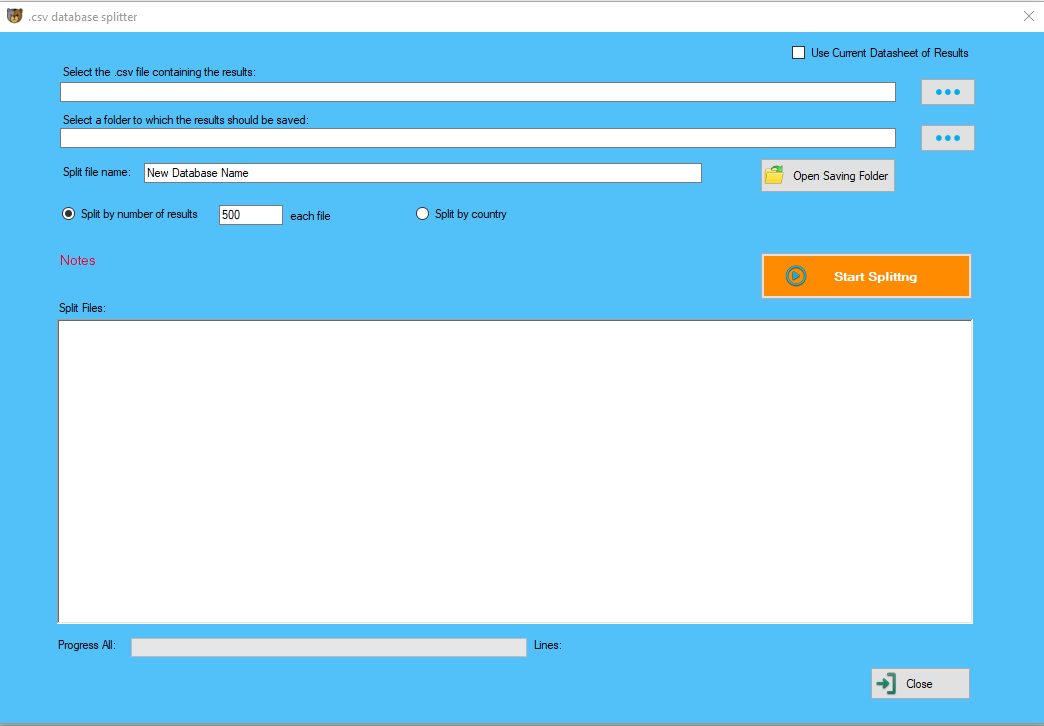
A chilled out evening at our head offices in Wapping with quality CBD coconut tinctures and CBD gummies from JustCBD @justcbdstore @justcbd @justcbd_wholesale https://t.co/s1tfvS5e9y#cbd #cannabinoid #hemp #london pic.twitter.com/LaEB7wM4Vg
— Creative Bear Tech (@CreativeBearTec) January 25, 2020