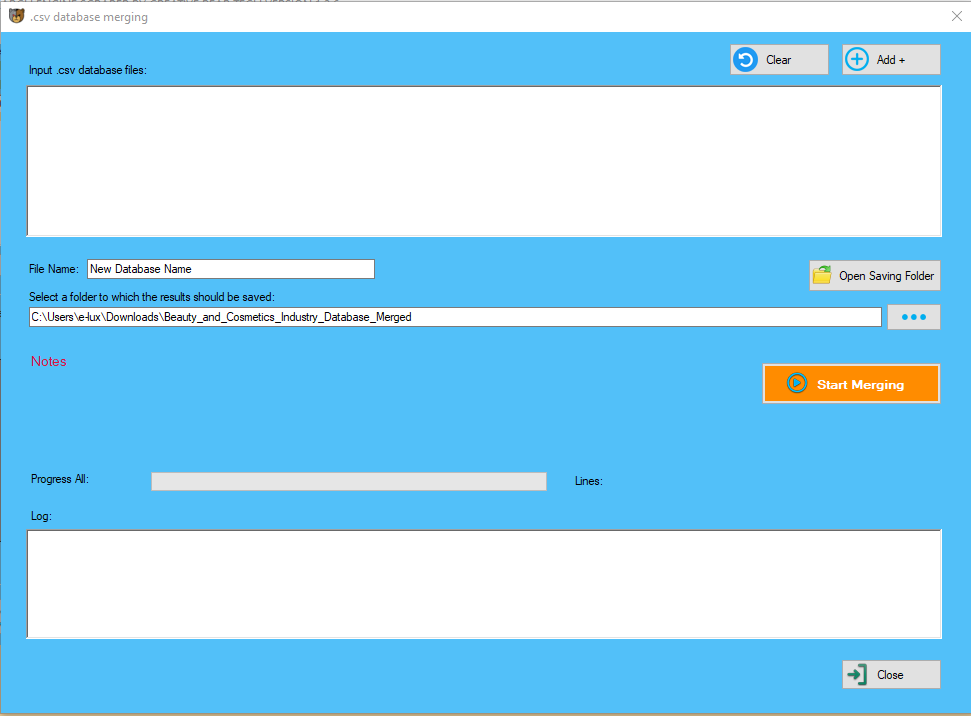
10 Data Extraction
What Is Data Extraction?
An essential source of bias in mannequin development is within the method of choosing the final predictors, particularly in research with a small pattern size. We break up the number of predictors into two parts, the number of predictors for inclusion within the multivariable analysis and selection during multivariable modelling.
Data Extraction Defined
The ETL Process staff ought to design a plan on the way to implement extraction for the initial hundreds and the incremental hundreds, firstly of the project itself. ETL tools are best suited to perform any complex data extractions, any number of instances for DW though they're costly.
How Is Data Extracted?
Women's Clothing and Apparel Email Lists and Mailing Listshttps://t.co/IsftGMEFwv
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
women's dresses, shoes, accessories, nightwear, fashion designers, hats, swimwear, hosiery, tops, activewear, jackets pic.twitter.com/UKbsMKfktM
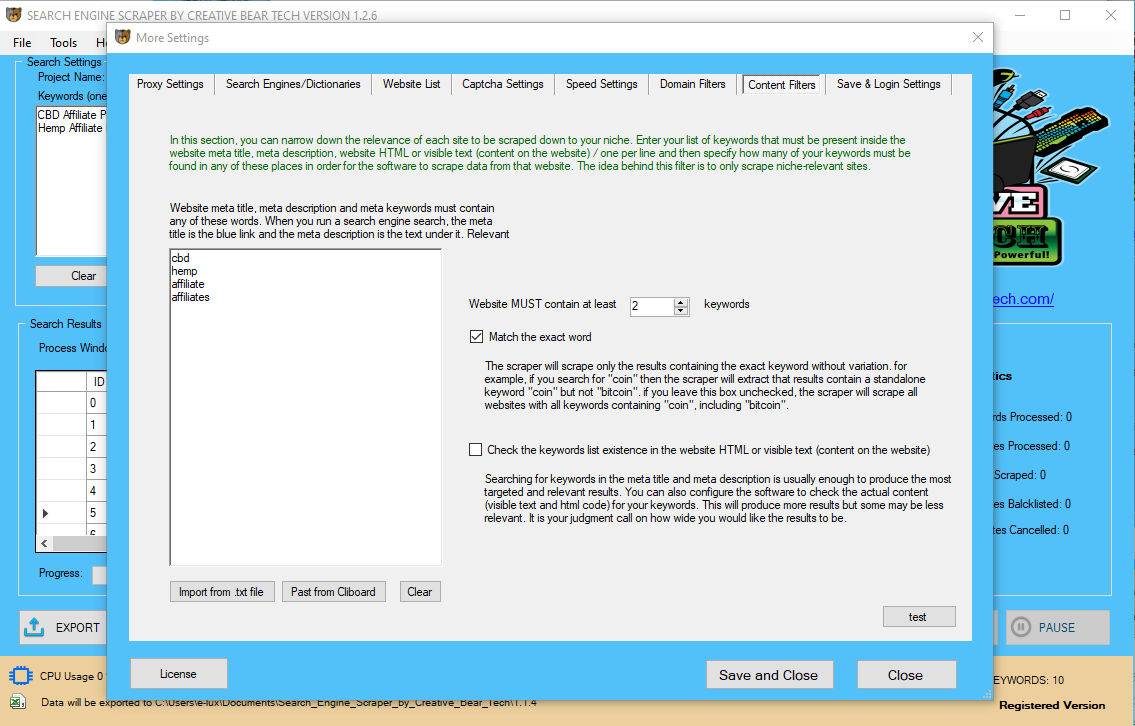
The use of different predictor selection methods and standards for predictor inclusion across research might yield completely different models and totally different quantities of bias. The strategies used to deal with predictors within the analysis can influence which predictors are chosen for inclusion within the mannequin and so affect mannequin predictions. Continuous or categorical predictors are incessantly dichotomised for the evaluation ,,,, regardless of sturdy evidence and suggestions on the contrary –. Categorisation assumes a continuing danger as much as the cut-level and then a special risk beyond the minimize-point, which is implausible and nonsensical. 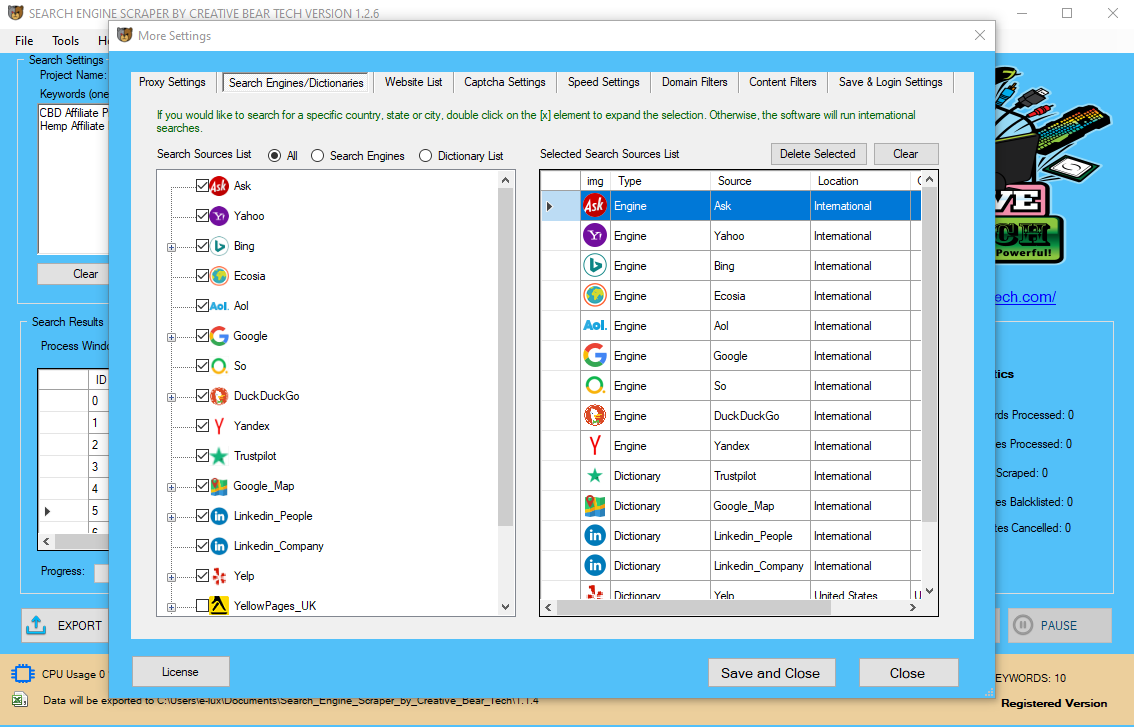
Structured Data
All the precise data sources and the respective data elements that assist the enterprise choices shall be mentioned in this document. A one-page checklist of related items to extract from individual research in a scientific evaluation of prediction models. As models are usually developed to estimate an individual's outcome chance, you will need to seize and record whether or not this can really be accomplished from the revealed model. Rounding or simplifying authentic predictor weights or regression coefficients is prone to trigger a loss in predictive accuracy. Hence, if related, the systematic review should report the performance measures of the unique and “rounded” models where this info is out there in the revealed primary report .
Unstructured Data
Data extraction software program considerably expedites the collection of related data for further evaluation by automating the method, giving organizations more management over the knowledge. In this text, we’ll define data extraction, discuss its benefits, and highlight standards for choosing the proper data extraction instruments . Transformation is the method the place a set of rules is applied to the extracted knowledge before immediately loading the source system data to the goal system. Once the initial load is completed, it is very important consider the way to extract the information that is modified from the supply system additional.
In addition, dichotomising discards information and commonly leads to a loss of power . Table 1 summarises key items to guide the framing of the review goal, search technique, and study inclusion and exclusion criteria. Table 2 and Text S1 describe the overall domains and particular items inside every domain to extract from the reports of primary prediction modelling research in gentle of the evaluate query, with a view to gauge threat of bias and applicability. An intrinsic a part of the extraction includes data validation to confirm whether or not the information pulled from the sources has the right/expected values in a given area (similar to a sample/default or record of values). Organizations that do leverage knowledge extraction tools substantially scale back the time for information-driven processes, leading to extra time for extracting useful insights out of knowledge. A comprehensive data extraction device should have the ability to assemble pertinent knowledge from webpage — based sources like e-commerce sites, emails, blogs, and mainstream information companies, as well as inner and exterior systems. In the last Data Extraction Tool with AI a number of years, net scraping has emerged as a method utilized by knowledge extraction instruments, significantly for the ETL process. Web scraping entails segmenting web pages and extracting related info. Often, priceless information, corresponding to customer info, is obtained from web scraping, which relies on various automation applied sciences including Robotic Process Automation (RPA), Artificial intelligence (AI), and machine learning. By utilizing a persistent metadata repository, ETL tools can transition from one-time projects to persistent middleware, performing information harmonization and information profiling constantly and in near-actual time. The range of knowledge values or information quality in an operational system may exceed the expectations of designers at the time validation and transformation guidelines are specified. Data profiling of a source during information analysis can determine the data situations that must be managed by transform guidelines specifications, leading to an modification of validation rules explicitly and implicitly applied in the ETL process. The load part masses the info into the top goal, which may be any knowledge store together with a easy delimited flat file or an information warehouse. Depending on the requirements of the group, this course of varies widely. For instance, if the evaluate goals to assess the performance of a specific prediction mannequin, then solely external validation research of that mannequin are applicable for the review. A centered evaluate query permits researchers to develop a tailor-made search technique and to outline the inclusion and exclusion standards—and thus the applicability—of major research included within the review. 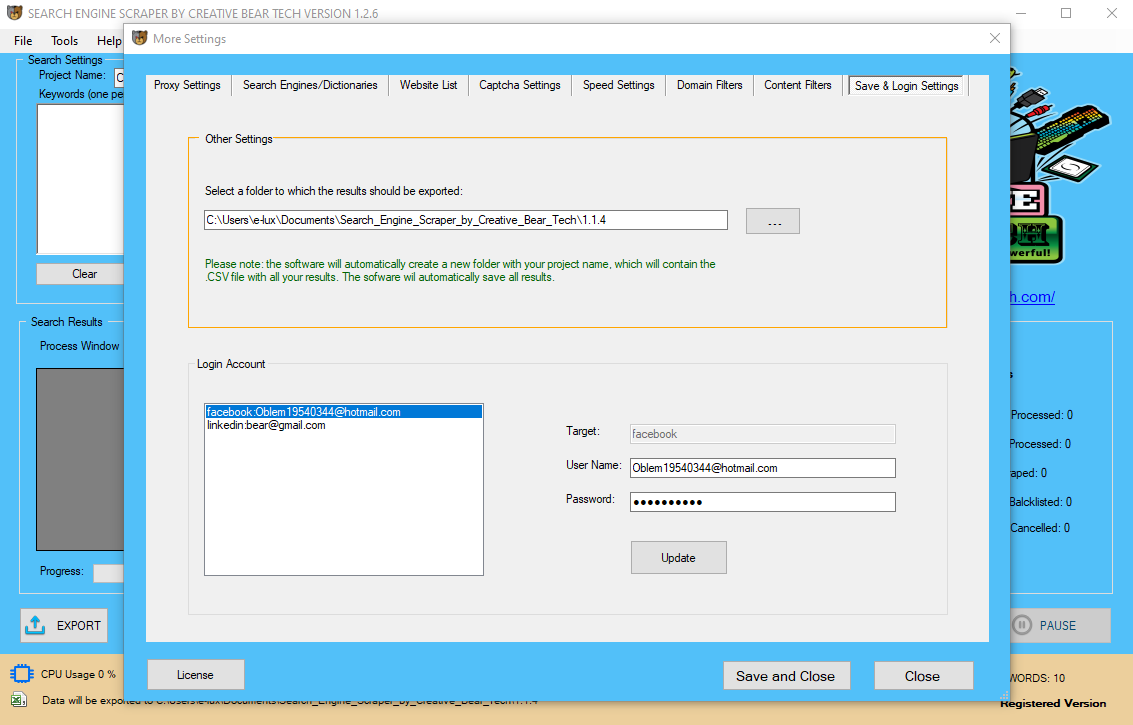 Calibration and discrimination should all the time be recorded when reviewing medical prediction fashions. Calibration refers to how well the expected risks evaluate to the observed outcomes; preferably that is evaluated graphically by plotting noticed towards predicted event charges ,,. Calibration plots are often supplemented by a proper statistical take a look at, the Hosmer-Lemeshow test for logistic regression and its equivalent for Cox regression. Data extraction is the place data is analyzed and crawled through to retrieve related data from knowledge sources (like a database) in a specific sample. Further data processing is completed, which entails adding metadata and other information integration; another process within the knowledge workflow. When used appropriately, information extraction tools can save your corporation time, giving staff time to focus on extra essential duties. is a group-pushed, searchable, web-based mostly catalogue of tools that help the systematic review process throughout multiple domains. Use the superior search choice to limit to instruments particular to information extraction. Some data warehouses might overwrite existing info with cumulative information; updating extracted information is frequently done on a every day, weekly, or month-to-month basis. Other data warehouses (or even different components of the same information warehouse) could add new knowledge in a historic form at common intervals — for instance, hourly. To understand this, contemplate a data warehouse that is required to take care of sales information of the last yr. However, the entry of knowledge for anyone yr window is made in a historical manner. Excel is essentially the most basic software for the administration of the screening and data extraction stages of the systematic evaluate course of. A extra advanced strategy to utilizing Excel for this function is the PIECES strategy, designed by a librarian at Texas A&M. The PIECES workbook is downloadable atthis guide. Stitch Data Loader offers a fast, fault-tolerant path to data extraction from greater than 90+ sources.
Calibration and discrimination should all the time be recorded when reviewing medical prediction fashions. Calibration refers to how well the expected risks evaluate to the observed outcomes; preferably that is evaluated graphically by plotting noticed towards predicted event charges ,,. Calibration plots are often supplemented by a proper statistical take a look at, the Hosmer-Lemeshow test for logistic regression and its equivalent for Cox regression. Data extraction is the place data is analyzed and crawled through to retrieve related data from knowledge sources (like a database) in a specific sample. Further data processing is completed, which entails adding metadata and other information integration; another process within the knowledge workflow. When used appropriately, information extraction tools can save your corporation time, giving staff time to focus on extra essential duties. is a group-pushed, searchable, web-based mostly catalogue of tools that help the systematic review process throughout multiple domains. Use the superior search choice to limit to instruments particular to information extraction. Some data warehouses might overwrite existing info with cumulative information; updating extracted information is frequently done on a every day, weekly, or month-to-month basis. Other data warehouses (or even different components of the same information warehouse) could add new knowledge in a historic form at common intervals — for instance, hourly. To understand this, contemplate a data warehouse that is required to take care of sales information of the last yr. However, the entry of knowledge for anyone yr window is made in a historical manner. Excel is essentially the most basic software for the administration of the screening and data extraction stages of the systematic evaluate course of. A extra advanced strategy to utilizing Excel for this function is the PIECES strategy, designed by a librarian at Texas A&M. The PIECES workbook is downloadable atthis guide. Stitch Data Loader offers a fast, fault-tolerant path to data extraction from greater than 90+ sources.
Search Engine Scraper and Email Extractor by Creative Bear Tech. Scrape Google Maps, Google, Bing, LinkedIn, Facebook, Instagram, Yelp and website lists.https://t.co/wQ3PtYVaNv pic.twitter.com/bSZzcyL7w0
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
- How a model was developed and validated and its reported efficiency give insight into whether the reviewed model is more likely to be helpful, and for whom.
- The checklist is designed to help form a evaluation query for and appraisal of all forms of major prediction modelling studies, together with, regressions, neural network, genetic programming, and vector machine studying fashions –,,,,–.
- Some objects, such as “number of predictors during multivariable modelling” and “mannequin presentation”, are considerably extra particular to regression approaches.
- Box 1 reveals the forms of prediction modelling studies for which the CHARMS guidelines was developed.
- All tools for reporting of medical research recommend discussing strengths, weaknesses, and future challenges of a study and its reported results –, including the PRISMA assertion for reporting of systematic evaluations itself .
The timing and scope to switch or append are strategic design choices depending on the time out there and the enterprise wants. More complex methods can maintain a historical past and audit path of all modifications to the data loaded within the information warehouse. Since the information extraction takes time, it's common to execute the three phases in parallel. While the data is being extracted, one other transformation process executes whereas processing the information already acquired and prepares it for loading whereas the data loading begins with out waiting for the completion of the earlier phases. Having access to timely knowledge is crucial for better decisions and clean enterprise operations. Last however not least, the most obvious profit depends on information extraction instruments’ ease of use. These tools present enterprise customers with a person interface that isn't only intuitive, however offers a visible view of the info processes and guidelines in place. Additionally, the need to hand code data extraction processes are eradicated—permitting for individuals without a programming talent set to extract insights. A study conducted by Forrester revealed that not more than zero.5 % of the world’s knowledge is analyzed and used. Data extraction permits users to extract meaningful info hidden inside unstructured information sources, similar to buyer churn price. In some scenarios, you would possibly extract comparable information sets from two completely different sources. You would then need to evaluation and course of the extractions to ensure that they are both formatted equally. Typical unstructured data sources embrace internet pages, emails, paperwork, PDFs, scanned text, mainframe stories, spool recordsdata, classifieds, and so on. which is additional used for gross sales or marketing leads. An automated data extraction software might help release staff, giving them extra time to focus on the core actions as an alternative of repetitive information collection duties. Automation makes it potential to streamline the complete process from the time knowledge enters the business to when it's saved in a knowledge warehouse after being processed, eliminating the necessity for guide work. Many companies nonetheless depend on their workers to manually extract key data saved in PDF information. The rejected knowledge is ideally reported again to the supply system for further analysis to establish and to rectify the wrong information. In computing, extract, remodel, load (ETL) is the final procedure of copying knowledge from a number of sources right into a destination system which represents the data differently from the supply(s) or in a unique context than the supply(s). The ETL process grew to become a preferred idea in the Nineteen Seventies and is usually utilized in data warehousing. Moreover, the person-pleasant interface of Astera ReportMiner simplifies information extraction, permitting business customers to build extraction logic in a completely code-free method. Employees are a important asset of any business, and their productiveness directly impacts a company’s possibilities of success.
Beauty Products & Cosmetics Shops Email List and B2B Marketing Listhttps://t.co/EvfYHo4yj2
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Beauty Industry Marketing List currently contains in excess of 300,000 business records. pic.twitter.com/X8F4RJOt4M
This may end up in errors, similar to incomplete records, missing data, and duplicates. Data mining not only guarantees valuable enterprise insights but in addition saves time, money, and sources concerned in guide extraction whereas ensuring data accuracy. ETL instruments can leverage object-oriented modeling and work with entities' representations persistently stored in a centrally situated hub-and-spoke architecture. Such a set that accommodates representations of the entities or objects gathered from the data sources for ETL processing is called a metadata repository and it can reside in memory or be made persistent. But please be aware that the enterprise intelligence environment is way more advanced. It involves methodology, purposes, and technologies to enable entire info processing. And a enough quantity of high quality information permits us to attract a conclusion from information analysis, uncover patterns and forecast future occasions, eliminate threat. They can be blogs, evaluations, posts, images, feedback, social engagements and more. Social media information extraction can explore enterprise alternatives, observe competitors, monitor consumer sentiment by extracting this information on a regular basis. Many companies are dependent on batch data extraction, which processes information sequentially depending on the user’s requirements. This implies that the information out there for analysis might not mirror the newest operational knowledge or crucial enterprise selections have to be based mostly on historic data. Hence, an efficient information extraction device should allow actual-time extraction with the assistance of automated workflows to organize knowledge sooner for enterprise intelligence. In easy terms, information extraction is the process of extracting data captured within semi structured and unstructured sources, corresponding to emails, PDFs, PDF forms, textual content recordsdata, barcodes, and images. An enterprise-grade knowledge extraction device makes incoming business data from unstructured or semi-structured sources usable for analytics and reporting. Modern knowledge extraction tools with constructed-in scheduler components help customers mechanically pull data from supply documents by making use of an acceptable extraction template and load structured knowledge to the target vacation spot. The first study you start knowledge extraction for in every review will turn out to be your "Review Template." The tables set up right here might be carried over to subsequently started extractions, the place they are often individually edited if wanted. Only the primary reviewer can edit the template; the first reviewer can be modified at any time by clicking "Manage reviewers" on the examine's pane Extraction web page. Using distributed-query know-how, one Oracle database can immediately query tables positioned in various different source techniques, similar to one other Oracle database or a legacy system related with the Oracle gateway technology. Specifically, an information 36 Best Lead Generation Tools to Get More Targeted Leads warehouse or staging database can instantly access tables and knowledge situated in a connected supply system. Gateways permit an Oracle database (corresponding to a knowledge warehouse) to entry database tables stored in remote, non-Oracle databases. To tackle attainable overfitting of a mannequin, shrinkage techniques can be utilized to regulate the estimated weights of the predictors. The corresponding adjusted estimates of predictive efficiency are more likely to be nearer to the predictive accuracy that will be found when the developed model is applied to different people. Hence, studies that develop prediction fashions which are adjusted or shrunk are much less vulnerable to bias. The want to be used of shrinkage methods will increase with smaller datasets, though in datasets with a low number of EPV, even shrinkage methods cannot account for all bias ,,,. It is essential to summarise and perceive key parts which may result in bias and variability between models.
Massive USA B2B Database of All Industrieshttps://t.co/VsDI7X9hI1 pic.twitter.com/6isrgsxzyV
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
This is the simplest technique for moving information between two Oracle databases because it combines the extraction and transformation right into a single step, and requires minimal programming. Data extraction doesn't necessarily mean that whole database structures are unloaded in flat information. In many cases, it might be applicable to unload entire database tables or objects. In different instances, it could be extra acceptable to unload solely a subset of a given table such as the changes on the supply system because the last extraction or the outcomes of becoming a member of a number of tables together. Often the unique dataset is randomly divided right into a improvement pattern and validation pattern. Moreover, the method is statistically inefficient because not all available information are used to develop the prediction model, increasing the chance of overfitting, significantly in small datasets. Thus, for small datasets, the use of cut up-sample methods actually increases the danger of bias, whilst for giant datasets there is no sensible benefit . If splitting the data is to be considered in giant datasets, then a non-random cut up is preferable, for instance splitting by time, centre, or geographic location ,,,,,. Regardless of the statistical technique used to develop or validate the model, varied mannequin efficiency measures similar to calibration, discrimination, (re)classification, and total measures of efficiency may be used ,,. The application of data virtualization to ETL allowed fixing the commonest ETL duties of knowledge migration and utility integration for multiple dispersed data sources. Virtual ETL operates with the abstracted representation of the objects or entities gathered from the variety of relational, semi-structured, and unstructured information sources.
Global Hemp Industry Database and CBD Shops B2B Business Data List with Emails https://t.co/nqcFYYyoWl pic.twitter.com/APybGxN9QC
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
This rising course of of data extraction from the online is referred to as "Web data extraction" or "Web scraping". Raw information is knowledge collected from a supply, which has not but been processed for utilization.Typically, the readily available information isn't in a state by which it may be used effectively for data extraction. Such data is difficult to manipulate and often needs to be processed indirectly, earlier than it can be used for knowledge evaluation and knowledge extraction in general, and is referred to as uncooked knowledge or supply information. The automation of knowledge extraction tools contributes to larger effectivity, particularly when considering the time concerned in amassing knowledge. Data extraction software program utilizing options for RPA, AI, and ML considerably hasten identifying and amassing relevant knowledge. Data extraction is a process that entails the retrieval of data from completely different sources in order to develop an understanding of the completely different options of it and to provide you with significant, necessary, and interesting attributes of this data. Data extraction can be used to carry out exploratory analysis and to extract related info from the information. Data extraction is the act or strategy of retrieving information out of (normally unstructured or poorly structured) data sources for additional data processing or knowledge storage (data migration). The import into the intermediate extracting system is thus often adopted by information transformation and probably the addition of metadata prior to export to another stage in the knowledge workflow. These are only a few examples of knowledge extraction purposes in enterprise intelligence. Relevant items to extract from individual studies in a scientific evaluation of prediction fashions for functions of description or evaluation of danger of bias or applicability. To consider the proliferation of prediction fashions, systematic evaluations are necessary and led to the formation of the Cochrane Collaboration Prognosis Reviews Methods Group ,. Since then, search methods for identifying prognostic and diagnostic prediction mannequin studies have been developed –, validated, and additional refined . Publications on medical prediction fashions have turn into ample for each prognostic and diagnostic functions. Systematic critiques of those studies are increasingly required to identify and critically appraise present evidence. However, such tests have incessantly been criticised because of the restricted statistical power to evaluate poor calibration and being oversensitive in massive samples ,,,. Furthermore, the Hosmer-Lemeshow check provides no indication of the path or magnitude of any miscalibration. Discrimination refers to how nicely the model differentiates between these with and with out the result and is usually assessed using the c-statistic, which is the equivalent to the realm-underneath-the-curve of a receiver working attribute curve. The c-statistic shouldn't be used as the only efficiency measure, nevertheless, since it is influenced by the distribution of predictor values and is commonly insensitive to inclusion of an extra predictor within the mannequin ,–. Different extraction strategies differ of their capabilities to assist these two scenarios. When it's attainable to effectively identify and extract solely essentially the most recently changed data, the extraction course of (in addition to all downstream operations within the ETL course of) could be far more efficient, because it must extract a a lot smaller volume of knowledge. Unfortunately, for many source techniques, identifying the lately modified data could also be tough or intrusive to the operation of the system. Change Data Capture is usually the most challenging technical issue in information extraction. Many data warehouses do not use any change-capture methods as a part of the extraction course of. Instead, complete tables from the supply techniques are extracted to the data warehouse or staging space, and these tables are compared with a earlier extract from the supply system to establish the modified knowledge. This method could not have important impact on the source techniques, nevertheless it clearly can place a considerable burden on the info warehouse processes, significantly if the info volumes are giant.